프로메테우스 Prometheus 설정 및 실행, PromQL 사용 방법

해당 포스팅은 'Spring Boot Actuator', 'Prometheus 개념 및 특징' 포스팅에서 이어지는 내용으로 prometheus.yml 파일을 통한 프로메테우스 설정 및 실행, 그리고 기본적인 PromQL 사용 방법에 대한 내용입니다.
메트릭을 가져오기 위해 actuator가 실행되어 있어야 하며, actuator에 대한 선행 작업이 필요하신 경우 아래 포스팅을 참고하시면 좋을 것 같습니다.
2023.09.09 - [Programming/Monitoring] - Spring Boot Actuator(+ Micrometor) 모니터링 시스템 구축 1편
(spring boot 프로젝트 기반 모니터링 시스템 구축 관련 포스팅)
다운로드 및 실행

prometheus는 공식 홈페이지를 통해 다운로드할 수 있으며, 각 os에 맞는 파일을 받아 압축 해제 후 실행할 수 있습니다.
(macOS의 경우 'darwin'을 받으면 됩니다.)
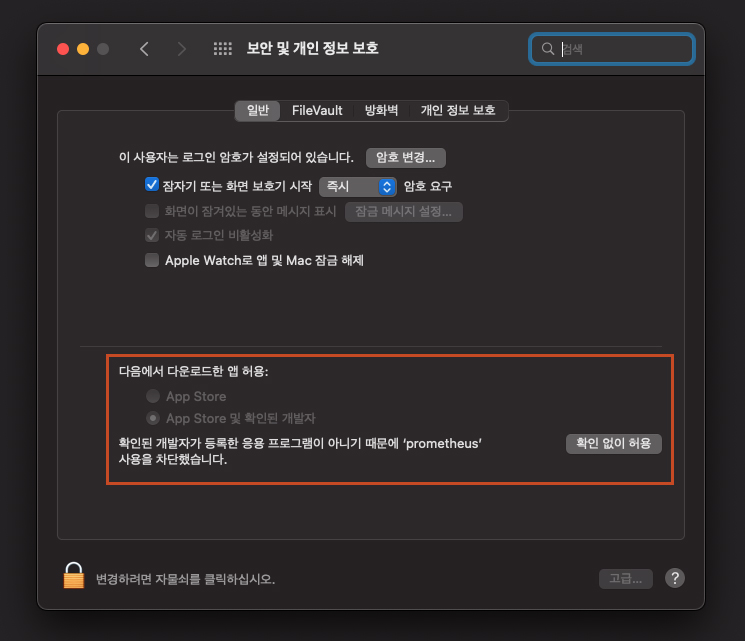
macOS의 경우 보안 문제로 인해 prometheus가 실행되지 않을 수도 있는데요.
그 경우 위 이미지와 같이 '시스템 환경설정' -> '보안 및 개인 정보 보호' -> '일반' 경로에서 prometheus에 대한 허용 절차가 필요합니다.

이어서 프로메테우스 실행 시 기본 포트인 9090 port로 실행되며, 해당 포트로 접속하여 다음과 같은 화면을 볼 수 있습니다.
* 현재 기본 설정으로 실행된 프로메테우스는 actuator로부터 methrics을 가져오지 않고 있는 상태이며, 아래 yml 설정을 통해 actuator와 연동을 적용해 보도록 하겠습니다.
yml 설정

우선 prometheus.yml 파일의 scrape_configs 하위에 다음과 같이 spring-boot-actuator 관련 정보를 추가해 주면 되는데요.
여기서 'job_name'의 경우 수집하는 메트릭의 이름으로 임의의 값을 사용하면 됩니다.
그리고 'metrics_path'는 메트릭을 수집할 경로이며, 'scrape_interval'은 메트릭 수집 주기입니다.
수집 주기(scrape_interval)가 너무 짧을 경우 애플리케이션 성능에 영향을 줄 수 있기 때문에 운영 환경에 맞는 값을 설정하는 것이 좋습니다.
(대부분 10s ~ 1m 정도가 권장된다고 합니다.)
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"](prometheus.yml 파일 전체 코드)
이어서 yml 파일의 전체 설정을 살펴보면 prometheus.yml 파일의 설정은 크게 'global', 'alerting', 'rule_files', 'scrape_configs' 4가지로 나뉘는데요.
global
'global'은 prometheus 서버의 전역 구성을 제어하는 부분입니다.
scrape_interval 옵션을 통해 프로메테우스가 대상의 메트릭 데이터를 가져오는 빈도를 설정할 수 있으며, 전역 구성에서 정의되어 있더라도 scrape_configs 부분에서 개별 대상에 대해 해당 값을 재정의할 수 있습니다.
evaluation_interval 옵션은 prometheus가 규칙을 평가하는 빈도를 제어하는 부분이며, 프로메테우스는 규칙을 통해 경고를 생성하거나 새로운 시계열 데이터를 생성할 수 있습니다.
alerting
'alerting' 부분을 통해서는 경고 관리 도구(Alertmanager)에 대한 설정을 할 수 있는데요.
경고와 관련된 부분은 추후 따로 기능을 작업해 보며 더 자세하게 포스팅할 예정입니다.
rule_files
'rule_files' 부분을 통해서는 프로메테우스 서버가 로드할 규칙의 위치를 설정할 수 있는데요.
해당 규칙은 global의 evaluation_interval 빈도와 연관되게 됩니다.
scrape_configs
마지막으로 'scrape_configs' 부분은 프로메테우스가 모니터링하는 리소스를 제어하는 데 사용되는데요.
보시는 것처럼 scrape_configs 설정에는 prometheus 자신에 대한 모니터링 설정도 포함되어 있습니다.
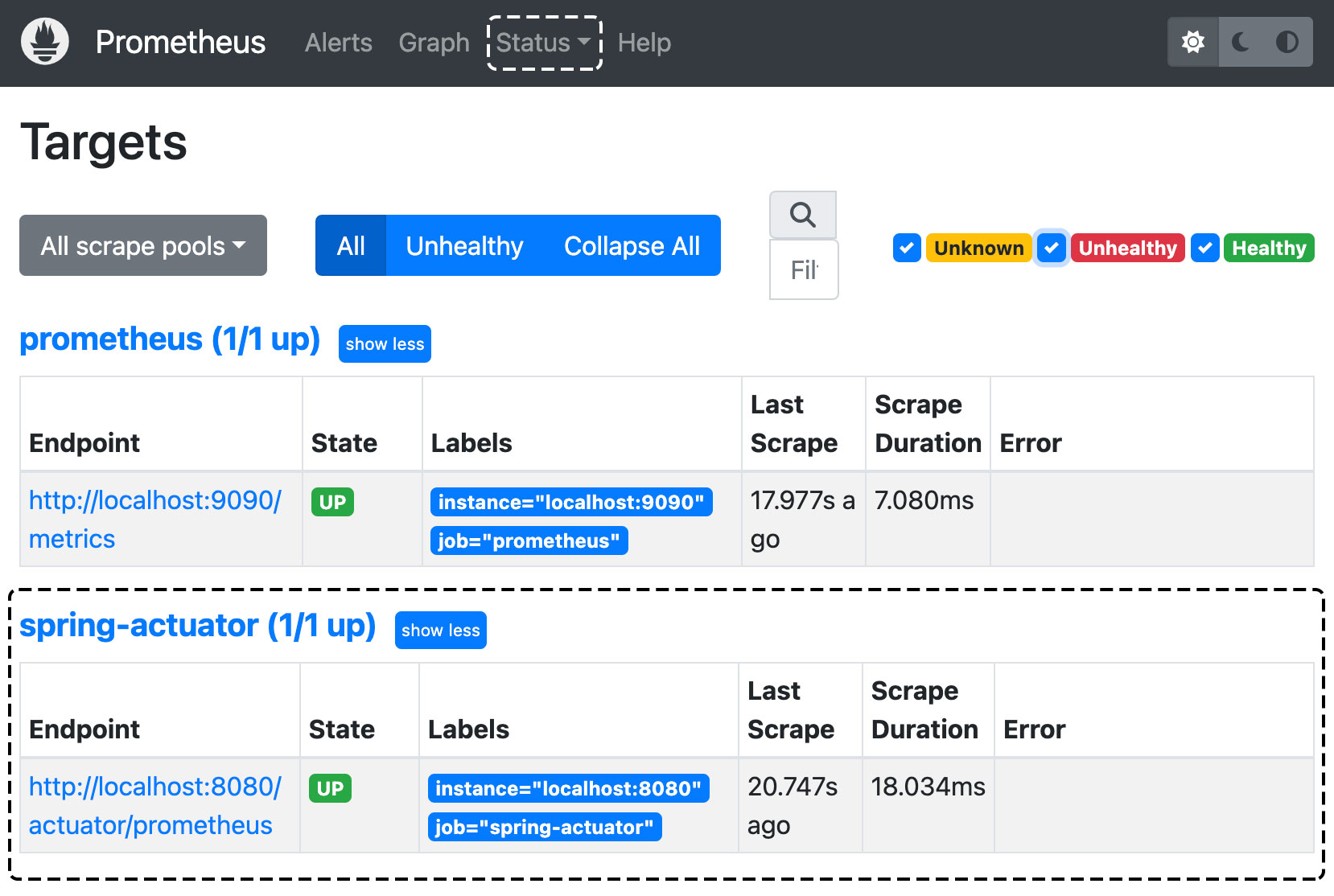
yml 파일 설정 후 프로메테우스를 재가동하고 해당 포트(9090 port)로 들어가 보면 'Status -> Configuration'를 통해 yml 파일에 추가한 데이터를 확인할 수 있고, 'Status -> Targets'에서 모니터링 대상에 추가한 spring actuator가 동작하고 있는 것을 확인할 수 있습니다.
(status 값이 up인 것은 메트릭이 정상적으로 수집되고 있다는 것입니다.)
PromQL
prometheus는 모니터링 대상으로부터 수집된 시계열 데이터를 실시간으로 조회하고 집계할 수 있는 PromQL(Prometheus Query Language)이라는 쿼리 언어를 사용하는데요.

http 요청이 몇 번이 들어왔는지 확인하는 'http_server_requests_seconds_count'를 예시로 검색해 보면 다음과 같은 결과를 확인할 수 있습니다.
여기서 error, instance, job, method, outcome, status, uri는 각 메트릭에 대한 정보를 구분하기 위해서 사용되는 값인데요.
프로메테우스에서는 이것을 레이블(Label)이라고 하고, 마이크로미터에서는 이것을 태그(Tag)라고 합니다.
(그리고 맨 오른쪽에 있는 숫자는 바로 해당 메트릭의 값이 됩니다.)

그리고 프로메테우스에서는 이 레이블을 기준으로 검색에 대한 필터를 적용할 수 있는데요.
필터는 위 이미지와 같이 '중괄호 {}' 문법을 사용하며, 이때 아래와 같은 레이블 일치 연산자를 사용할 수 있습니다.
// = : 제공된 문자열과 정확히 동일한 라벨을 선택합니다.
http_server_requests_seconds_count{uri="/actuator/prometheus"}
// != : 제공된 문자열과 동일하지 않은 라벨을 선택합니다.
http_server_requests_seconds_count{uri!="/actuator/prometheus"}
// =~ : 제공된 문자열과 정규식이 일치하는 라벨을 선택합니다.
http_server_requests_seconds_count{uri=~"/actuator/prometheus"}
// !~ : 제공된 문자열과 정규식이 일치하지 않는 라벨을 선택합니다.
http_server_requests_seconds_count{uri!~"/actuator/prometheus"}
Prometheus는 위 예시와 같은 기본적인 데이터 조회 외에도 데이터 작업을 위한 다양한 기능(ceil, floor, round, sort, sum, sum by, topk 등)을 제공하는데요.
해당 기능들의 세부적인 내용에 대해서는 프로메테우스 공식 문서를 참고해 주시면 좋을 것 같습니다.

마지막으로 메트릭 측정 결과는 크게 '임의로 오르내릴 수 있는 값인 게이지(Gauge)'와 '단순하게 증가하는 단일 누적 값인 카운터(Counter)' 두 가지로 분류될 수 있는데요.
위와 같은 카운터 측정 결과는 계속 증가하기만 하기 때문에 '특정 시간에 대한 메트릭 값을 확인하기가 어렵다는 단점'이 있습니다.
때문에 카운터 값을 그래프화 할 때는 '범위 벡터의 시계열 증가를 계산하는 increase()' 또는 '범위 벡터에서 시계열의 초당 평균 증가율을 계산하는 rate()' 기능 등을 사용하여 위 이미지와 같이 특정 시간에 대한 메트릭 값을 나타낼 수 있습니다.
여기까지 Prometheus의 기본 설정 및 실행, PromQL의 기본적인 사용법을 살펴보았습니다.
이처럼 프로메테우스를 통해 모니터링 대상에서 수집된 메트릭 데이터를 확인하거나 그래프화 할 수는 있지만, 여러 가지 메트릭에 대한 데이터를 한 번에 볼 수는 없다는 단점이 있는데요.
이를 해결하기 위해 수집된 메트릭의 시각화를 담당하는 'Grafana'를 연동해서 사용하게 됩니다.
이어지는 포스팅에서는 Grafana의 개념과 특징 그리고 프로메테우스와 그라파나를 연동하는 방법에 대해 살펴보도록 하겠습니다.
(해당 포스팅은 김영한 님의 '스프링 부트 -핵심 원리와 활용' 강의 내용을 기반으로 하여 추가로 공부한 것을 기록하였습니다.)
< Prometheus 공식 문서 >
https://prometheus.io/docs/prometheus/latest/querying/basics/
< 관련 포스팅 >
2023.09.15 - [Programming/Monitoring] - Prometheus 개념 및 특징 정리, 모니터링 시스템 구축 2편
< 참고 자료 >
'Programming > Monitoring' 카테고리의 다른 글
| Prometheus 개념 및 특징 정리, 모니터링 시스템 구축 2편 (0) | 2023.09.15 |
|---|---|
| Spring Boot Actuator(+ Micrometor) 모니터링 시스템 구축 1편 (0) | 2023.09.09 |