
해당 내용은 IN / NOT IN / EXISTS / NOT EXISTS 동작 방식을 정리한 내용으로 MySQL을 기준으로 실행하고 작성된 내용이지만 MSSQL, Oracle 등에서도 적용되는 내용입니다.

(예시에 사용될 orders table, customers table입니다.)
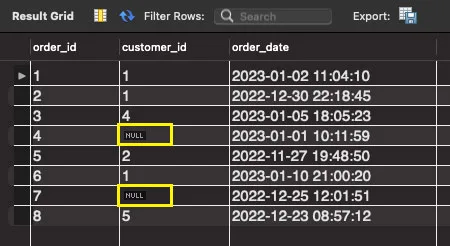
(예시에 사용될 orders table의 data입니다.)
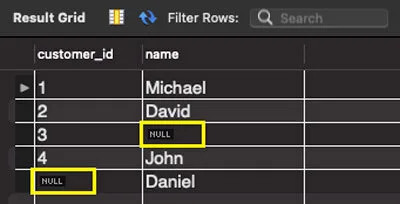
(예시에 사용될 customers table의 data입니다.)
IN
SELECT * FROM orders o WHERE o.customer_id IN (1, 2);
-- or 연산자로 변환된 쿼리
SELECT * FROM orders o WHERE (o.customer_id = 1 OR o.customer_id = 2);in 구문의 경우 in 구문에 입력된 값들 중에서 하나라도 일치하는 것이 있으면 조회됩니다. 즉, 쿼리가 실행될 때 내부적으로 or 연산자로 변경되어 실행되는 것인데요.
in 구문의 장점으로는 in 연산자에 다른 select 문을 넣을 수 있다는 것(=서브쿼리)이며, 대량의 값을 대입하거나 동적으로 값이 변경되어야 할 때 in 연산자에 서브쿼리를 사용할 수 있습니다.
/*
MySQL 5.6에서 서브쿼리가 대폭 개선되었으며, MySQL 5.5 까지는 서브쿼리의 최적화 성능이 좋지 않아 Join으로 전환하여 실행되는 것이 좋습니다. MySQL 5.6부터는 서브쿼리 사용 시 내부적으로 Join으로 실행됩니다.
*/
-- in
SELECT * FROM orders o
WHERE o.customer_id IN (SELECT c.customer_id FROM customers c);이어서 in 구문에서 서브쿼리를 사용했을 때 동작되는 방식을 살펴보겠습니다.
해당 쿼리에서는 먼저 in 구문에 있는 서브쿼리가 실행되는데요.
서브쿼리를 먼저 실행해서 그에 대한 결과 요소들을 가지고 온 뒤, 메인 쿼리인 orders 테이블에서 하나의 row를 가져오며, 해당 row의 customer_id 값이 in 구문이 실행된 결과 값들 중 하나라도 일치한다면 그 row를 출력하게 되는 방식입니다.
(그리고 위 과정을 메인 쿼리의 row 개수만큼 반복하여 비교하게 됩니다.)

서브쿼리의 내용인 customers 테이블의 customer_id 값들을 조회하면 (1, 2, 3, 4, null)이 됩니다.
그리고 orders 테이블의 row를 하나씩 가지고 와서 서브쿼리의 결과인 (1, 2, 3, 4, null) 중에서 일치하는 값이 있는지 확인하여 출력합니다.
***
orders table의 customer_id 값이 null 인 row에서 서브쿼리의 결과 중 null 이 있으니까 출력되어야 하는 게 아닌가 생각할 수 있는데요. 출력되지 않는 이유를 살펴보면 null 값은 DB에서 비교연산을 할 때 항상 UNKNOWN(= false) 값을 반환하기 때문에 출력되지 않는 것입니다.
NOT IN
-- not in1
SELECT * FROM orders o
WHERE o.customer_id NOT IN (SELECT c.customer_id FROM customers c);in 구문이 위와 같은 방식으로 서브쿼리의 결과를 포함하는 결과를 반환했다면, not in 구문이 사용된 쿼리의 경우 말 그대로 서브쿼리의 결과 요소들과 일치하지 않는 값을 체크하여 반환해 주게 됩니다.
in 구문의 경우 서브쿼리의 결과로 나온 값들 중 일치하는 값이 하나라도 있으면 되지만, 반대로 not in을 사용하면 서브쿼리의 결과로 나온 모든 값들과 일치하지 않는지를 체크하게 됩니다.
즉, in 구문의 경우 내부적으로 or 연산자로 변경되었던 반면, not in 구문의 경우 and 연산자로 변경된다는 차이점이 있는데요.

해당 쿼리의 실행 결과입니다.
서브쿼리의 실행 결과를 먼저 살펴보면 위 in 구문과 같이 (1, 2, 3, 4, null)이 나오는데요.
***
위에서 not in 구문이 서브쿼리의 결과로 나온 모든 값들과 일치하지 않는지를 체크한다고 했는데, 그러면 orders table의 custom_id가 5인 row는 출력되어야 하는 게(1, 2, 3, 4, null 모든 값들과 일치하지 않기 때문에) 아닌지라고 생각할 수 있습니다.
이 결과 역시 DB에서 null 값을 비교연산하며 발생한 것인데요.
customer_id = 5와 1, 2, 3, 4 값을 != 비교를 했을 때 모두 true 가 나오지만 5와 null을 비교했을 때는 UNKNOWN(= false) 값이 반환되므로 and 연산자로 묶인 해당 쿼리에 대한 결과가 false가 되어 출력되지 않는 것입니다.
-- not in2
SELECT * FROM orders o
WHERE o.customer_id NOT IN (SELECT c.customer_id FROM customers c WHERE c.customer_id IS NOT NULL);때문에 not in 구문에서 원하는 결과를 보기 위해서는 다음과 같이 null을 제외하는 조건을 추가해줘야 하는데요.
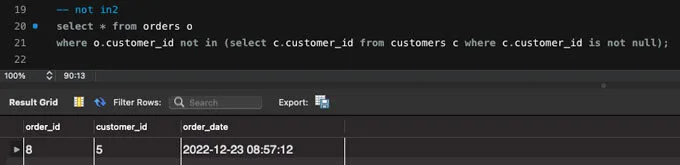
이렇게 is not null 조건을 추가했을 때 원하는 결과를 얻을 수 있습니다.
EXISTS
-- exists1
SELECT * FROM orders o
WHERE EXISTS (SELECT c.customer_id FROM customers c);exists 구문에서는 in 구문과 다르게 메인 쿼리에 먼저 접근하여 row를 하나 가져오고 exists의 서브쿼리를 실행시켜 결과가 존재하는지를 판단합니다.
서브쿼리의 결과가 true 인지 false 인지 체크하기 때문에 exists에서는 결과가 존재할 경우(= true) 메인 쿼리의 결과를 출력하고 not exists에서는 서브쿼리 내의 결과가 존재하지 않을 경우(= false) 메인 쿼리의 결과를 출력하게 됩니다.
(in 연산자는 비교할 값을 직접 대입할 수 있지만 exists 연산자는 서브쿼리만 사용할 수 있다는 특징이 있습니다.)
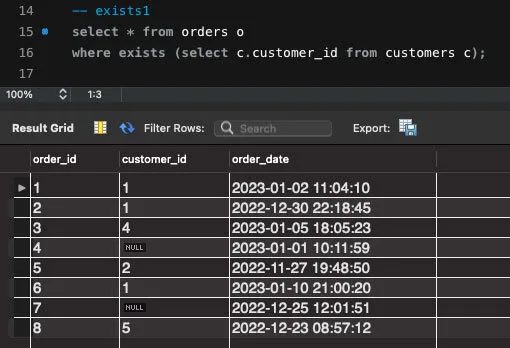
서브쿼리에서 결과가 존재하는지만을 판단하기 때문에 customer_id가 null인 row까지 출력되는 것을 확인할 수 있는데요.
-- exists2
SELECT* FROM orders o
WHERE EXISTS (SELECT c.customer_id FROM customers c WHERE c.customer_id = o.customer_id);따라서 두 테이블에서 같은 값을 가지고 오려면 다음과 같이 where 절을 추가로 적용시켜 주어야 합니다.
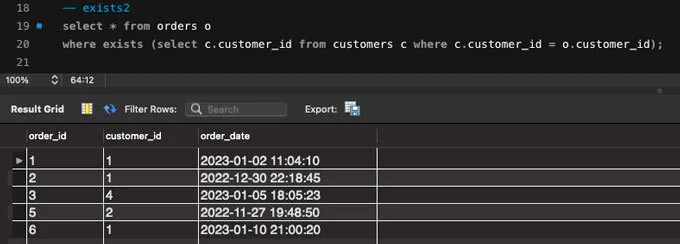
이렇게 나온 결과는 in 구문과 같은 결과를 출력하지만 내부적으로 쿼리가 동작하는 방식은 다르며, 동작 방식이 다르기 때문에 성능의 차이도 있다는 것은 꼭 알아두어야 하는 부분입니다.
/*
in 연산자와 exists 연산자의 차이점은 in 연산자의 경우 무조건 서브쿼리의 모든 행을 검색하여 해당 값(customer_id)을 in 연산자에 대입하는 반면, exists 연산자는 서브쿼리에 해당하는 값을 1건이라도 찾으면 검색을 멈추고 true를 반환한다는 차이점이 있습니다.
즉, in 연산자는 서브쿼리를 모두 검색하고, exists 연산자는 찾을 때까지만 검색하는 것인데요.
따라서 서브쿼리의 데이터가 작을 경우 in 구문과 exists 구문의 성능은 크게 차이가 없지만, 서브쿼리에 조회되는 데이터가 많아질수록 exists 연산자를 사용한 쿼리의 성능이 더 좋은 것입니다.
*/
NOT EXISTS
-- not exists
SELECT * FROM orders o
WHERE NOT EXISTS (SELECT c.customer_id FROM customers c WHERE c.customer_id = o.customer_id);
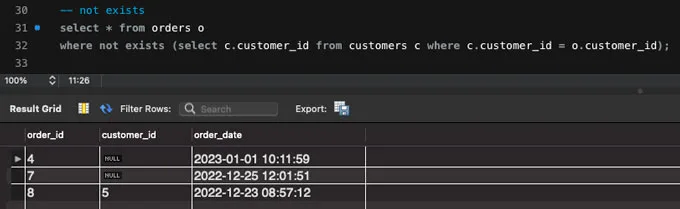
not exists 구문은 not in 구문과 다르게 null 값을 가진 row들도 결과에 포함되는 것을 확인할 수 있는데요.
orders 테이블의 customer_id = null 인 row가 출력되는 과정을 살펴보겠습니다.
결과의 첫 번째 row인 order_id = 4인 row를 예로 들었을 때 customer_id = null입니다. 따라서 not exists 이하의 쿼리를 확인해 보면 아래와 같을 것인데요.
SELECT c.customer_id FROM customers c WHERE c.customer_id = null;이 경우 DB에서 null 값 비교로 인해 not exists 구문의 결과는 UNKNOWN(= false)가 되고 not exists 구문은 결과가 존재하지 않는(= false)인 경우 출력되기 때문에 order_id = 4인 row가 출력되는 것입니다.
(order_id = 7인 row 역시 마찬가지입니다.)
< 참고 자료 >
https://doorbw.tistory.com/222
'Programming > Database' 카테고리의 다른 글
| Java Enum 타입 데이터베이스 저장 형식은 뭐가 좋을까? (enum, varchar, tinyint) (0) | 2023.04.02 |
|---|---|
| MariaDB 가상 필드를 통한 JSON 인덱싱 방법(Generated Columns) (0) | 2023.01.21 |
| 데이터 타입 CHAR, VARCHAR의 차이점, 무엇을 써야할까? (0) | 2022.06.22 |
| 트리구조 DB 설계 방법 - 클로저 테이블(Closure Table) (0) | 2022.06.15 |
| DB 데이터베이스 인덱스(Index) 기본 개념과 설명 (0) | 2022.02.12 |